forked from Shiloh/githaven
- Inline math blocks couldn't be preceeded or succeeded by alphanumerical characters due to changes introduced in PR #21171. Removed the condition that caused this (precedingCharacter condition) and added a new exit condition of the for-loop that checks if a specific '$' was escaped using '\' so that the math expression can be rendered as intended. - Additionally this PR fixes another bug where math blocks of the type '$xyz$abc$' where the dollar sign was not escaped by the user, generated an error (shown in the screenshots below) - Altered the tests to accomodate for the changes Former behaviour (from try.gitea.io):  Fixed behaviour (from my local build): 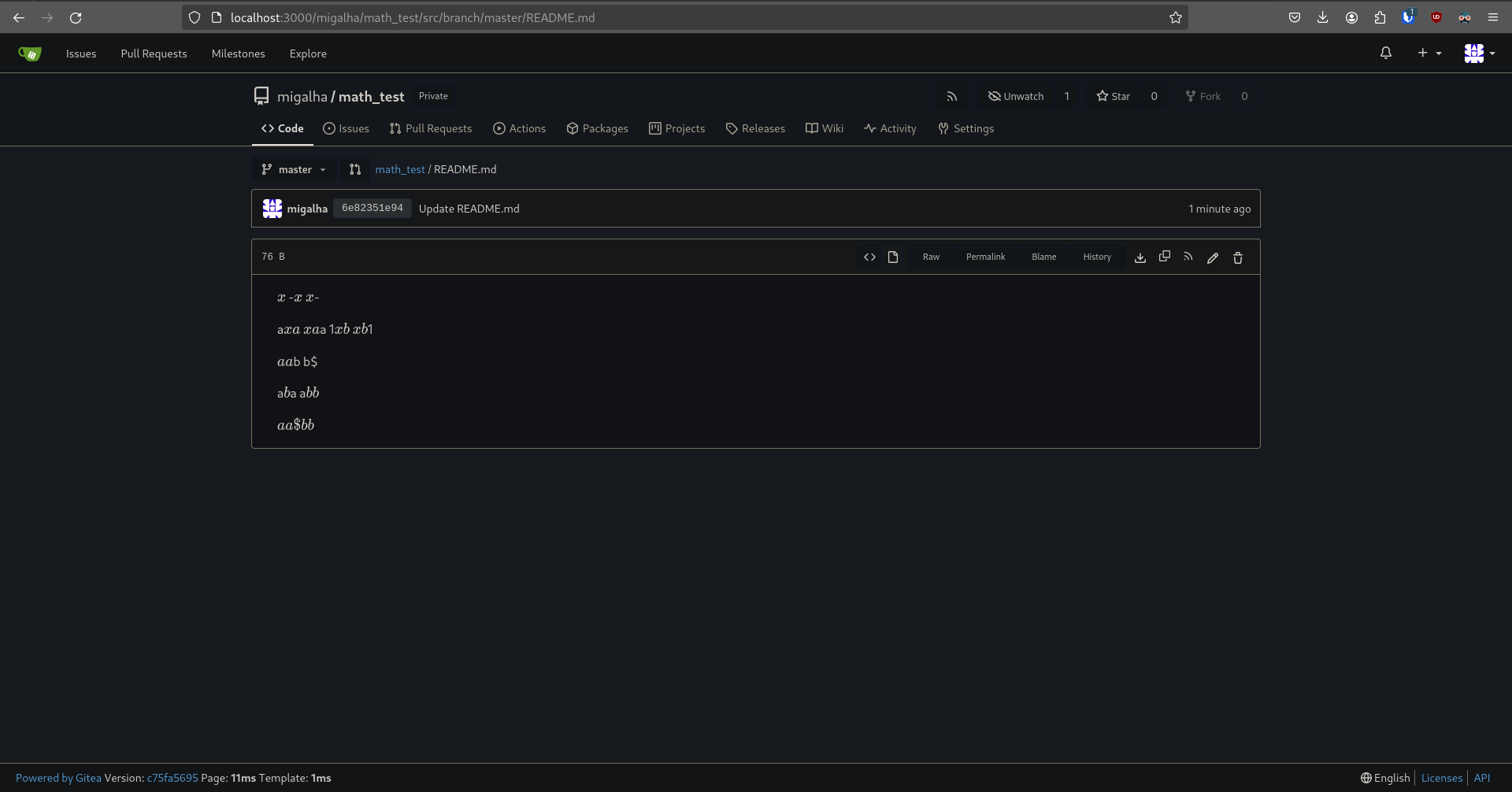 (Edit) Source code for the README.md file: ``` $x$ -$x$ $x$- a$xa$ $xa$a 1$xb$ $xb$1 $a a$b b$ a$b $a a$b b$ $a a\$b b$ ``` --------- Signed-off-by: João Tiago <joao.leal.tintas@tecnico.ulisboa.pt> Co-authored-by: Giteabot <teabot@gitea.io>
128 lines
3.1 KiB
Go
128 lines
3.1 KiB
Go
// Copyright 2022 The Gitea Authors. All rights reserved.
|
|
// SPDX-License-Identifier: MIT
|
|
|
|
package math
|
|
|
|
import (
|
|
"bytes"
|
|
|
|
"github.com/yuin/goldmark/ast"
|
|
"github.com/yuin/goldmark/parser"
|
|
"github.com/yuin/goldmark/text"
|
|
)
|
|
|
|
type inlineParser struct {
|
|
start []byte
|
|
end []byte
|
|
}
|
|
|
|
var defaultInlineDollarParser = &inlineParser{
|
|
start: []byte{'$'},
|
|
end: []byte{'$'},
|
|
}
|
|
|
|
// NewInlineDollarParser returns a new inline parser
|
|
func NewInlineDollarParser() parser.InlineParser {
|
|
return defaultInlineDollarParser
|
|
}
|
|
|
|
var defaultInlineBracketParser = &inlineParser{
|
|
start: []byte{'\\', '('},
|
|
end: []byte{'\\', ')'},
|
|
}
|
|
|
|
// NewInlineDollarParser returns a new inline parser
|
|
func NewInlineBracketParser() parser.InlineParser {
|
|
return defaultInlineBracketParser
|
|
}
|
|
|
|
// Trigger triggers this parser on $ or \
|
|
func (parser *inlineParser) Trigger() []byte {
|
|
return parser.start[0:1]
|
|
}
|
|
|
|
func isPunctuation(b byte) bool {
|
|
return b == '.' || b == '!' || b == '?' || b == ',' || b == ';' || b == ':'
|
|
}
|
|
|
|
func isAlphanumeric(b byte) bool {
|
|
return (b >= 'a' && b <= 'z') || (b >= 'A' && b <= 'Z') || (b >= '0' && b <= '9')
|
|
}
|
|
|
|
// Parse parses the current line and returns a result of parsing.
|
|
func (parser *inlineParser) Parse(parent ast.Node, block text.Reader, pc parser.Context) ast.Node {
|
|
line, _ := block.PeekLine()
|
|
|
|
if !bytes.HasPrefix(line, parser.start) {
|
|
// We'll catch this one on the next time round
|
|
return nil
|
|
}
|
|
|
|
precedingCharacter := block.PrecendingCharacter()
|
|
if precedingCharacter < 256 && (isAlphanumeric(byte(precedingCharacter)) || isPunctuation(byte(precedingCharacter))) {
|
|
// need to exclude things like `a$` from being considered a start
|
|
return nil
|
|
}
|
|
|
|
// move the opener marker point at the start of the text
|
|
opener := len(parser.start)
|
|
|
|
// Now look for an ending line
|
|
ender := opener
|
|
for {
|
|
pos := bytes.Index(line[ender:], parser.end)
|
|
if pos < 0 {
|
|
return nil
|
|
}
|
|
|
|
ender += pos
|
|
|
|
// Now we want to check the character at the end of our parser section
|
|
// that is ender + len(parser.end) and check if char before ender is '\'
|
|
pos = ender + len(parser.end)
|
|
if len(line) <= pos {
|
|
break
|
|
}
|
|
suceedingCharacter := line[pos]
|
|
if !isPunctuation(suceedingCharacter) && !(suceedingCharacter == ' ') {
|
|
return nil
|
|
}
|
|
if line[ender-1] != '\\' {
|
|
break
|
|
}
|
|
|
|
// move the pointer onwards
|
|
ender += len(parser.end)
|
|
}
|
|
|
|
block.Advance(opener)
|
|
_, pos := block.Position()
|
|
node := NewInline()
|
|
segment := pos.WithStop(pos.Start + ender - opener)
|
|
node.AppendChild(node, ast.NewRawTextSegment(segment))
|
|
block.Advance(ender - opener + len(parser.end))
|
|
|
|
trimBlock(node, block)
|
|
return node
|
|
}
|
|
|
|
func trimBlock(node *Inline, block text.Reader) {
|
|
if node.IsBlank(block.Source()) {
|
|
return
|
|
}
|
|
|
|
// trim first space and last space
|
|
first := node.FirstChild().(*ast.Text)
|
|
if !(!first.Segment.IsEmpty() && block.Source()[first.Segment.Start] == ' ') {
|
|
return
|
|
}
|
|
|
|
last := node.LastChild().(*ast.Text)
|
|
if !(!last.Segment.IsEmpty() && block.Source()[last.Segment.Stop-1] == ' ') {
|
|
return
|
|
}
|
|
|
|
first.Segment = first.Segment.WithStart(first.Segment.Start + 1)
|
|
last.Segment = last.Segment.WithStop(last.Segment.Stop - 1)
|
|
}
|